Edizione digitale delle lettere di Vincenzo Bellini
Scelte editoriali
Il progetto Bellini Digital Correspondence è volto a fornire, in un’edizione scientifica digitale, la conservazione a lungo termine, la pubblicazione sul web e la fruizione di 40 lettere scritte dal celebre compositore Vincenzo Bellini (1801-1835) e conservate presso il Museo civico Belliniano di Catania.
Il progetto – che nella fase di realizzazione si è avvalso del contributo di studenti e tirocinanti del corso di Codifica dei Testi di Informatica Umanistica dell’Università di Pisa, specialmente nel lavoro di codifica dei testi – è rivolto idealmente a un’utenza diversificata, che comprende sia ricercatori in ambito accademico, sia appassionati di musica e visitatori del Museo civico Belliniano.
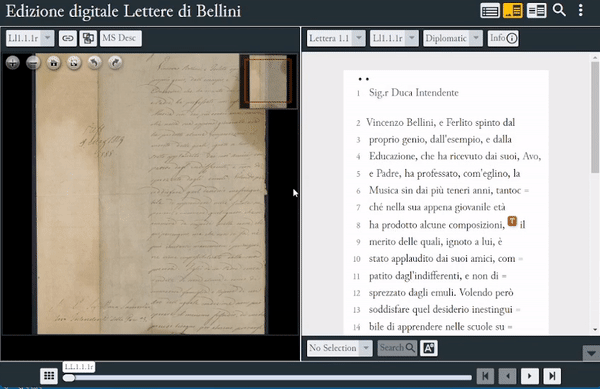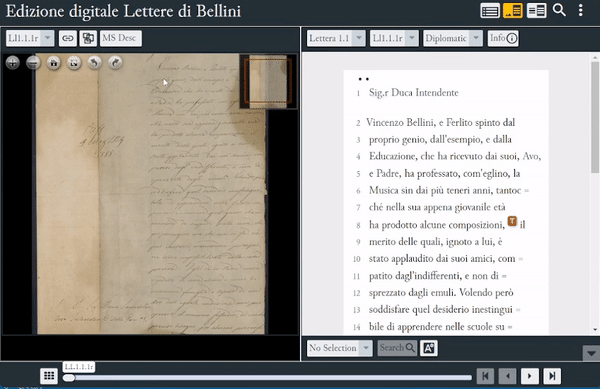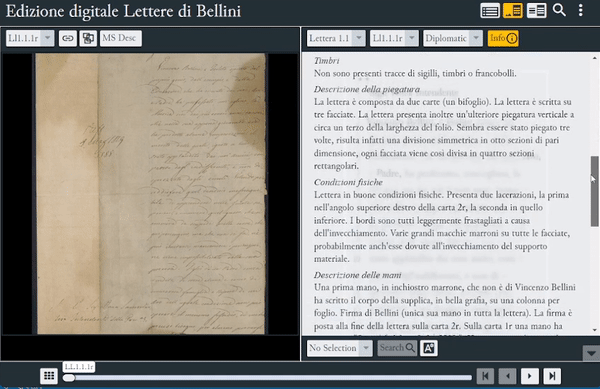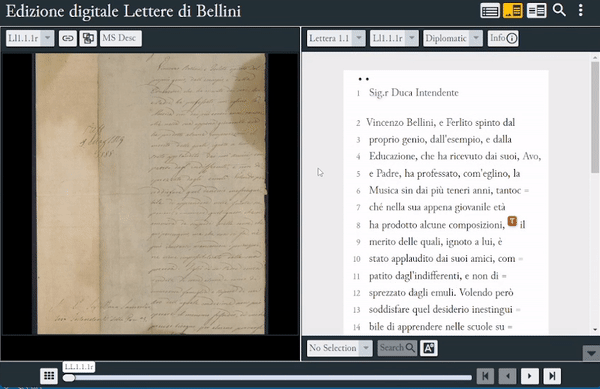
Le lettere, le minute e i biglietti della corrispondenza presi in esame nel progetto sono stati scritti in un arco di tempo che interessa gran parte della vita del musicista, e che si estende dal 1819 al 1835. Ogni documento è rappresentato da una o più immagini digitalizzate ad alta risoluzione, acquisite attraverso apparecchiature specifiche, che riproducono le singole carte (recto e verso).
Immagini digitalizzate di alcune lettere del corpus belliniano
Grazie alla cortesia della Casa Editrice Leo S.Olschki, al fine di garantire la correttezza scientifica delle trascrizioni, le lettere che compongono il repertorio sono state trascritte sulla base dell’edizione critica a stampa curata da Graziella Seminara e pubblicata nel 2017.
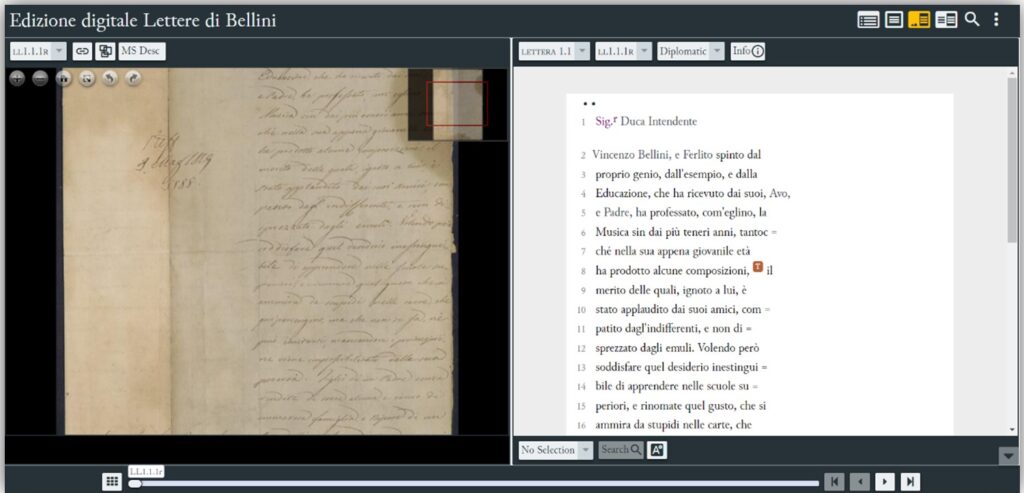
Bellini Digital Correspondence è, invece, un’edizione totalmente digitale: il corpus epistolare è stato codificato in XML secondo lo standard TEI, in base alle ultime linee guida TEI P5, ed è reso accessibile via web grazie al software open source EVT – Edition Visualization Technology, nella versione Beta 2. Il viewer EVT fornisce le funzionalità per la vista parallela testo-immagine a granularità di riga (nonché la visualizzazione di hotspot).
Visualizzazione dell'edizione in EVT
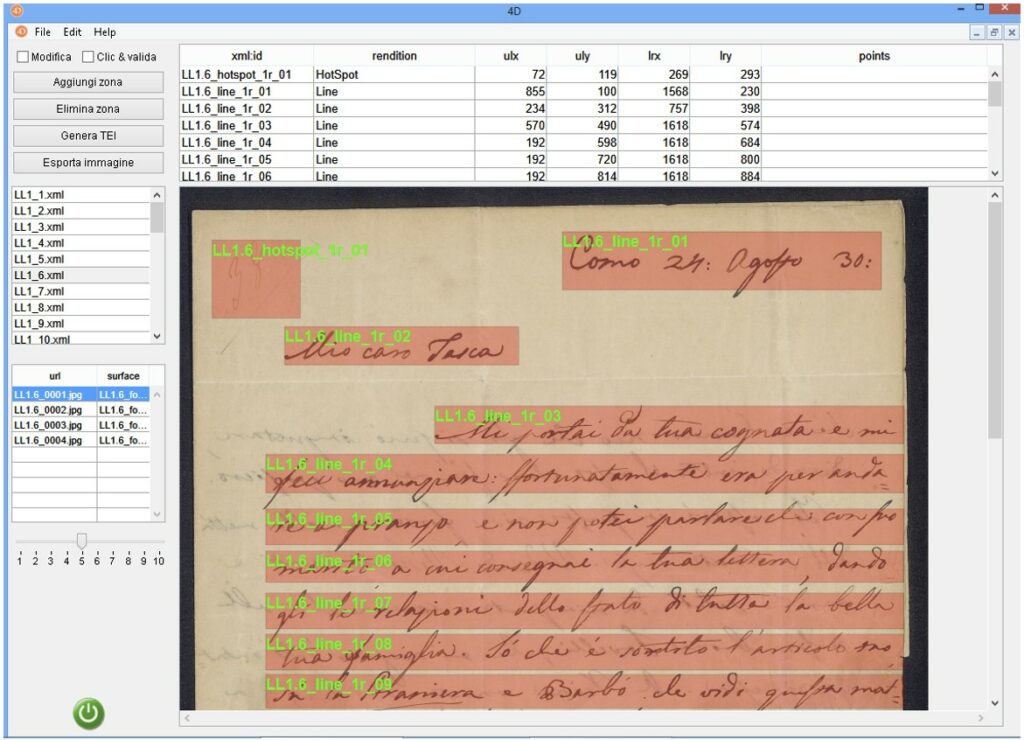
Per la realizzazione di Bellini Digital Correspondence, inoltre, sono stati utilizzati alcuni altri strumenti, tra cui ZoneRW (Zone Read White), tool WYSIWYG di verifica e correzione delle aree disegnate sulle immagini. ZoneRW è stato sviluppato utilizzando 4th Dimension, comunemente chiamato 4D, ambiente RAD per database relazionali prodotto e manutenuto dalla società francese 4D SAS e ampiamente utilizzato a livello mondiale nel mondo accademico.
Schermata principale ZoneRW
Indichiamo qui di seguito alcune delle principali caratteristiche della presente edizione:
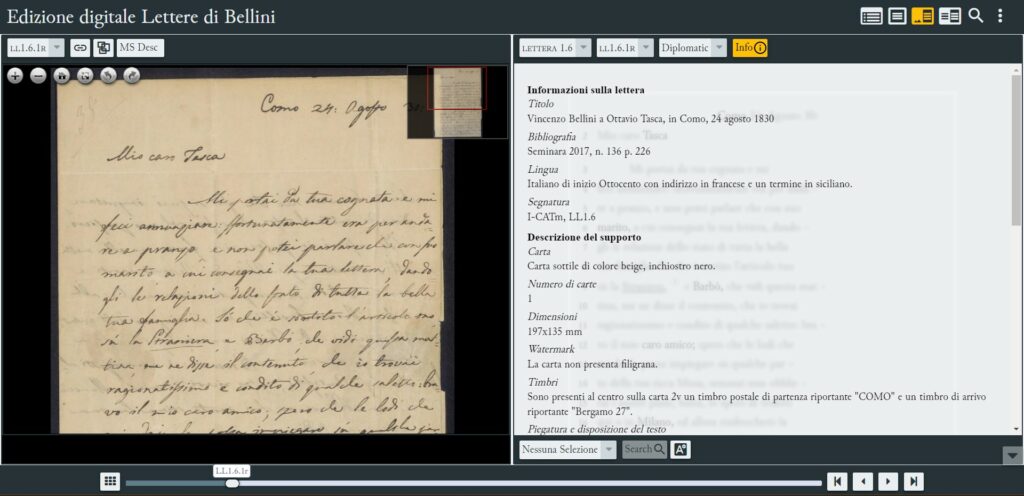
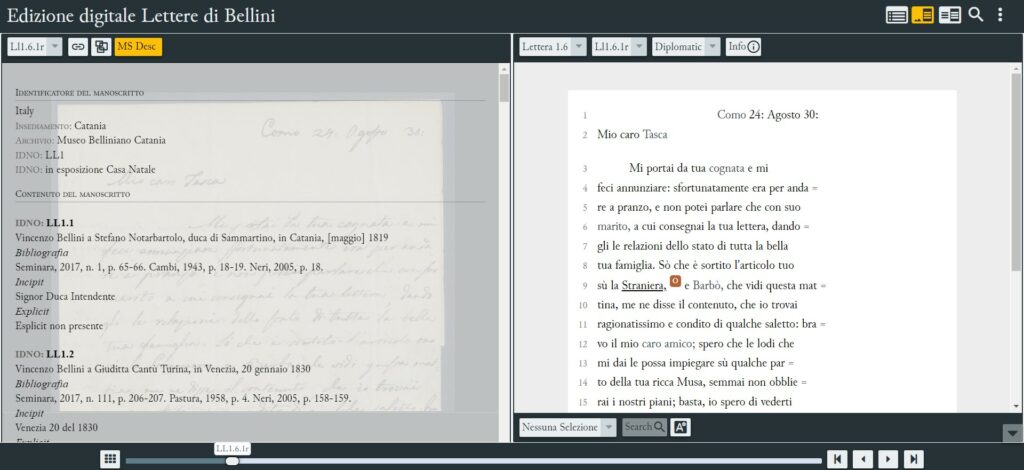
Nella sezione Info, l’edizione offre una descrizione codicologica della fonte primaria, compresi alcuni cenni sulla condizione fisica del documento, sul tipo e le dimensioni della carta utilizzata, sull’inchiostro, sulla disposizione del testo e delle piegature, oltre alle informazioni sulla corrispondenza, ove presenti o deducibili, e ai dati paratestuali (timbri, sigilli, informazioni catalografiche). La sezione MsDesc, invece, offre un riepilogo dei metadati e dei contenuti testuali per ciascun item del corpus, compresi incipit ed explicit della lettera, e la relativa bibliografia.
Attivazione delle sezioni "Ms Desc" e "Info"
Sezione Info di EVT
Sezione MsDesc di EVT
Le trascrizioni della corrispondenza sono corredate da note e commenti al testo: a tal proposito si riportano le osservazioni presenti in Seminara2017 (fatta eccezione per specifici casi, di cui si segnala la responsabilità). Il testo evidenzia anche la presenza di eventuali entità nominate (nomi di persona e di luogo, nomi di enti) e di opere e termini musicali. Per questi ultimi, si è fatto riferimento al volume pubblicato da Carocci, a cura di Fabrizio Della Seta. Ciascuno di tali elementi è consultabile in apposite liste. Ove si è ritenuto necessario, inoltre, si è provveduto all’integrazione dei dati e al collegamento con risorse online e repository pubblici autorevoli.
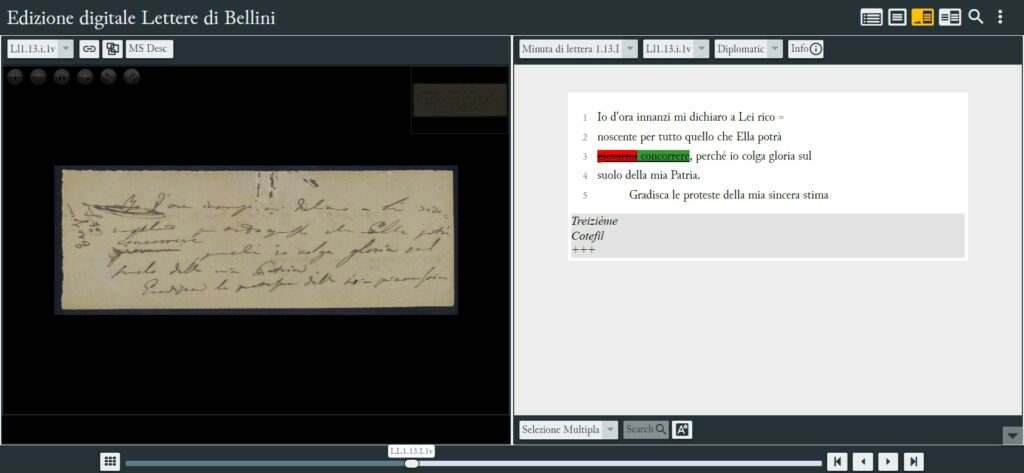
Gli interventi autoriali sono evidenziati nella trascrizione diplomatica, con colore rosso (cancellature, lacune) e verde (aggiunte in riga, a margine o in interlinea).
Interventi autoriali (cancellatura e aggiunta in interlinea) in EVT
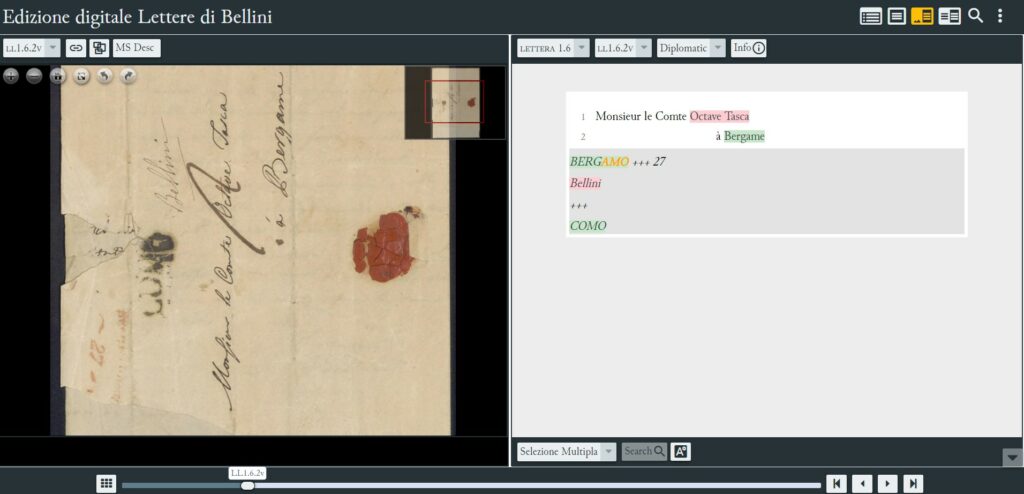
Differenziazioni tipografiche segnalano invece la presenza di paratesto e di mani non belliniane.
Paratesto evidenziato in grigio
In generale, nella trascrizione del testo non sono state attuatenormalizzazioni linguistiche (interpunzione, ortografia, arcaismi). Data la natura digitale della presente edizione, tuttavia, si sono rese necessarie alcune modifiche nelle norme editoriali dell’edizione a stampa, segnalate graficamente da colori e stili del testo.
A fronte della particolarità del corpus edito, si è reso necessario codificare elementi specifici del testo epistolare, come ad esempio le informazioni concernenti le caratteristiche specifiche del manoscritto, che sono state inserite nel tagset <msDesc> – elemento fondamentale del modulo Manuscript Description delle Guidelines TEI – a sua volta all’interno di <sourceDesc>. Anche elementi specifici della corrispondenza (le formule d’esordio e quelle di saluto, eventuali indirizzi e date, le firme e così via) hanno trovato posto nel lavoro di codifica, a partire dal <teiHeader>.
Nell’elemento <profileDesc>, ad esempio, oltre alla classificazione dell’oggetto lettera e alla lingua di scrittura, è contenuto il tagset <correspDesc>, essenziale per un’accurata codifica della corrispondenza: qui sono infatti codificati i nomi di mittente e destinatario, il luogo e la data di spedizione e ricezione e il contesto della comunicazione. Il tagset <correspDesc>, inoltre, permette di indicizzare le lettere mediante il web service CorrespSearch, un database internazionale che ad oggi conta oltre 150 mila lettere e 10 mila corrispondenti.
<profileDesc> <correspDesc> <correspAction type="sent"> <persName ref="TEI-ListPerson.xml#VB" role="composer">Vincenzo Bellini</persName> <placeName ref="TEI-ListPlace.xml#Put">Puteaux</placeName> <date when="1834-06-27">27 giugno 1834</date> </correspAction> <correspAction type="received"> <persName ref="TEI-ListPerson.xml#CP" role="librettist">Carlo Pepoli</persName> <placeName ref="TEI-ListPlace.xml#Paris">Paris</placeName> <date when="1834-06-27">27 giugno 1834</date> </correspAction> <correspContext> <p>Non è presente un contesto di riferimento</p> </correspContext> </correspDesc> [...] <profileDesc>
In <teiHeader> sono inoltre codificate informazioni riguardanti la descrizione della fonte manoscritta (<objectDesc>): sono indicati, ad esempio, il tipo di supporto usato (<material> in <support>), le condizioni fisiche della fonte manoscritta (<condition>), la presenza di timbri (<stamp>), di filigrana (<watermark>), di piegature (<collation>). A queste si aggiunge, in <handDesc>, la codifica di eventuali annotazioni di altre mani, diverse da quella belliniana: nel viewer EVT queste informazioni sono riportate in un apposito spazio della pagina, segnalato da uno sfondo grigio.
Nel corpo delle lettere, invece, le convenzioni che regolano la corrispondenza hanno trovato riscontro in tag specifici, tra cui:
<div type=”opener”> per codificare le formule d’esordio tipiche della grammatica epistolare, composte da indirizzo e data di spedizione in alto a destra (<placeName> e <date> annidati in <dateLine>, con l’aggiunta di <address> nel caso in cui si riporti non solo la città o il paese da cui si invia la lettera, ma un vero e proprio indirizzo del mittente).
<div type=”letter_body”> per definire il corpo della lettera, compreso il saluto rivolto al destinatario (codificato in <salute>) che lo introduce.
<space> per dar conto dell’accurata prossemica, che nell’uso epistolare belliniano è sempre proporzionale al rapporto gerarchico con il destinatario.
<address> per marcare semanticamente gli indirizzi scritti nel corpo della lettera; <addrLine> è utilizzato, in aggiunta, per marcare semanticamente la parte di testo corrispondente ad una specifica riga di testo occupata interamente da un indirizzo (è quanto si verifica, in particolare, nell’imbustamento, che nelle missive belliniane è spesso parte integrante della lettera stessa);
<distinct>, per dar conto di parole dialettali; <orig>, invece, per segnalare ortografie particolari.
<abbr> e <expan> per indicare le numerose abbreviazioni e i relativi scioglimenti, in cui la porzione di testo esplicitata è riportata all’interno del tag <ex>; <g> codifica inoltre la presenza di un glifo e <am> di uno specifico segno di abbreviazione.
<div type=”closer”> per codificare le formule di congedo, in cui <salute> può marcare i consueti saluti finali (come, ad esempio, l’espressione Vostro affezionatissimo), <signed> le varie tipologie di firma di Bellini e <div type=”postscript”> eventuali scritti in calce.
Per citare questa pagina:
Del Grosso, Angelo Mario, Laura Mazzagufo e Daria Spampinato, Norme editoriali e di codifica, <http://bellinicorrespondence.cnr.it/scelte-editoriali/> [consultato il GG/MM/AAAA], in Bellini Digital Correspondence, a cura di A. M. Del Grosso e D. Spampinato, Cnr Edizioni, 2023, <http://bellinicorrespondence.cnr.it>, ISBN: 978-88-8080-562-5.
Per citare l’edizione:
Bellini Digital Correspondence, a cura di A. M. Del Grosso e D. Spampinato, Cnr Edizioni, 2023, <http://bellinicorrespondence.cnr.it> [consultato il GG/MM/AAAA], ISBN: 978-88-8080-562-5.