Edizione digitale delle lettere di Vincenzo Bellini
Strumenti
ZoneRW
La fruizione web dell’edizione è stata notevolmente migliorata da una fase di ottimizzazione della gestione delle immagini. In particolare, le attività hanno previsto sia lo sviluppo del tool ZoneRW (Zone Read Write) per la verifica delle coordinate delle regioni d’interesse, sia la realizzazione delle versioni in formato piramidale delle immagini originali e sia la creazione delle miniature per ciascuna singola lettera.
ZoneRW è stato sviluppato utilizzando 4th Dimension, comunemente chiamato 4D, ambiente RAD per database relazionali prodotto e manutenuto dalla società francese 4D SAS.
Per quanto riguarda l’individuazione delle zone da segnalare per la corrispondenza tra immagine e relativo contenuto testuale del file TEI, siano esse linee di testo oppure hotspot, è ampiamente utilizzato lo strumento TEI Zoner. Sfortunatamente, in caso di errori anche minimi, è necessario ripetere tutto il processo, lavoro insostenibile per il progetto BDC poiché gli elementi zone superano le 1200 unità. Inoltre, il tool non fornisce la visualizzazione a posteriori delle aree tracciate a partire dalle coordinate. Di conseguenza, per accelerare sia la visualizzazione che la correzione delle zone è stata sviluppata l’applicazione ZoneRW.
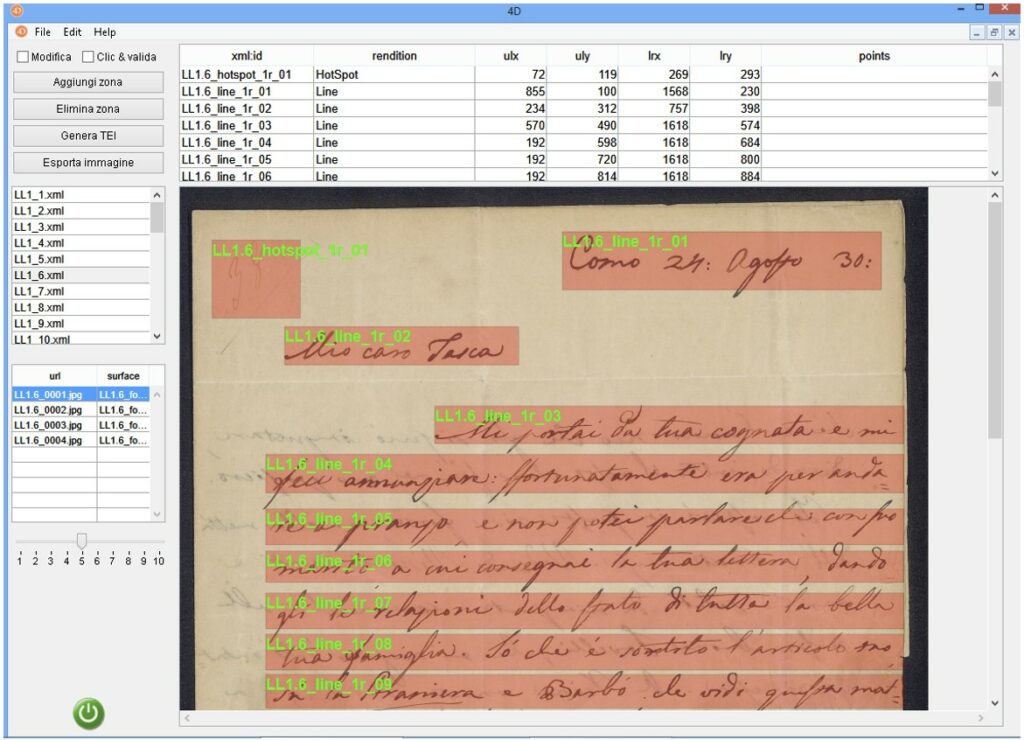
Schermata principale ZoneRW
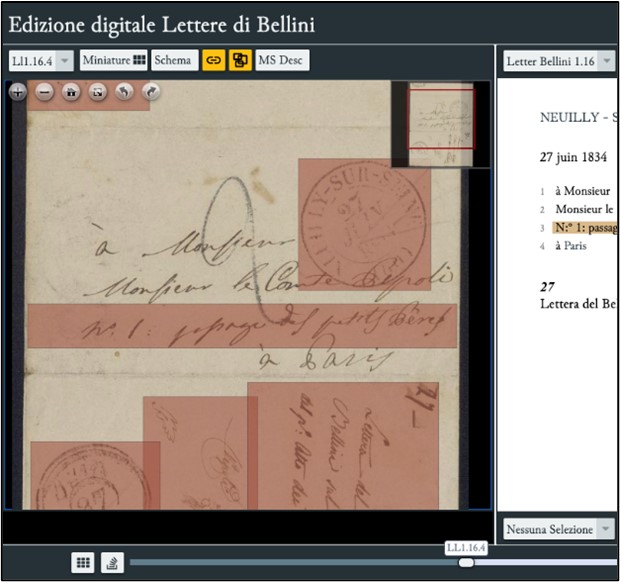
ZoneRW è un tool WYSIWYG che, a partire dalla dichiarazione delle surface con i relativi elementi graphic e zone, mostra le regioni codificate nel file TEI con i relativi attributi @xml:id e @rendition, consentendone la contestuale modifica (aggiornamento delle coordinate, aggiunta o rimozione di zone) e generando il corrispondente codice XML-TEI. Il risultato presente a video può essere esportato anche in formato immagine (ad esempio JPG) ottenendo così una vista delle aree che sia indipendente dal tool di creazione. In questo modo, i dati associati alle differenti zone delle immagini vengono correttamente estratti dal software EVT al fine di evidenziare le regioni d’interesse sovrapposte alle immagini facsimilari. Infatti, il viewer fornisce le funzionalità per la vista parallela testo-immagine a granularità di riga (attivabile tramite il pulsante con l’icona link) nonché la visualizzazione degli hotspot mediante il relativo pulsante posto nella barra degli strumenti al di sopra dell’immagine.
Schermata di EVT viewer con evidenziate le zone di interesse (linee e hotspot).
L’edizione del corpus belliniano è frutto di un processo distribuito che si è sviluppato lungo diverse fasi volte alla rappresentazione digitale delle fonti mediante numerose attività svolte in modo collaborativo e cooperativo.
Una delle fasi editoriali più delicate del progetto si è concentrata sul processo di verifica e armonizzazione delle lettere – necessario per via della molteplicità delle soluzioni di codifica prodotte dagli studenti – e ha previsto:
la revisione e/o la registrazione di molteplici fenomeni testuali e paratestuali nel documento digitale,
il completamento delle liste di entità nominate e altri dati notevoli,
la codifica dei collegamenti a risorse e repertori autorevoli disponibili sul web secondo le pratiche dei Linked Open Data (ad esempio, VIAF, GeoNames, RISM),
la revisione delle regioni d’interesse a partire dalle fonti facsimilari.
Per supportare la fase di armonizzazione, il team di BDC ha quindi ritenuto opportuno sviluppare un tool per il controllo dei fenomeni codificati in XML-TEI in maniera complessiva ed organica per tutte le risorse in esame. L’implementazione dell’algoritmo ha portato allo sviluppo di un componente che può essere integrato nello strumento ZoneRW oppure eseguito come strumento stand-alone.
Il tool NormaTEI ha innanzitutto il compito di raccogliere complessivamente i dati di codifica presenti nei file. L’algoritmo implementato restituisce il nome degli elementi, degli attributi e dei relativi valori.
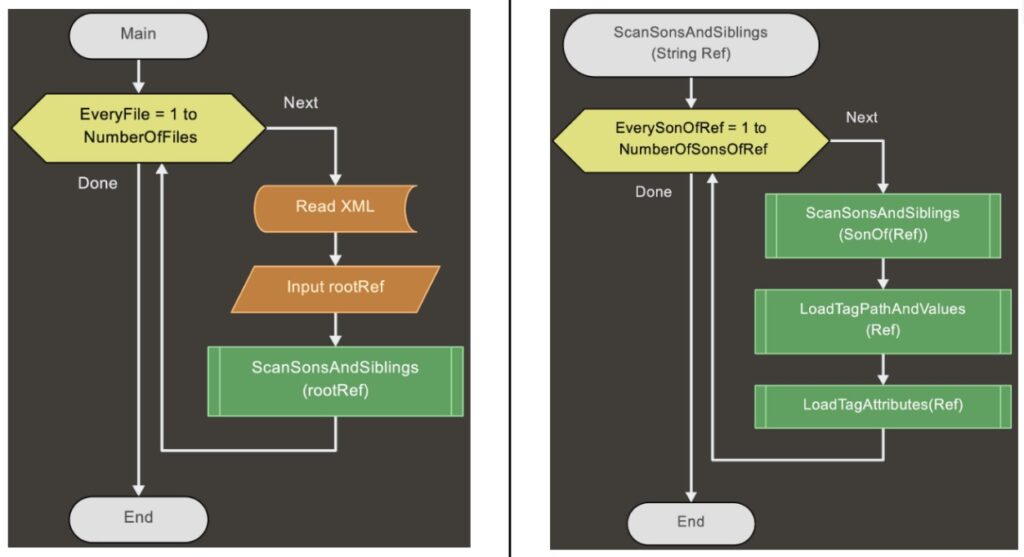
Per ognuno dei file XML-TEI da analizzare, l’algoritmo crea un puntatore alla radice della struttura XML del file (il tag <TEI>) e lancia la procedura ScanSonsAndSiblings. Questa prende come parametro il puntatore a un nodo (alla prima esecuzione è la radice della struttura del file) e viene chiamata ricorsivamente per ogni figlio del nodo; al termine di ogni ricorsione vengono memorizzati il tag attuale e il suo valore, il suo percorso completo, i suoi attributi e i rispettivi valori.
In questo modo si ottengono tutti i dati e le informazioni per l’intero albero XML-TEI di ogni file. Dall’osservazione di questi dati è possibile eseguire una serie di controlli sulla similarità: a esempio, più tag con il medesimo percorso potrebbero dover assumere lo stesso valore; tag con lo stesso nome e con lo stesso livello di profondità o simile (tutt’al più con una oscillazione di un livello nella gerarchia) potrebbero dover avere lo stesso percorso; più attributi con lo stesso nome potrebbero dover registrare lo stesso valore; attributi identici riferiti allo stesso tag potrebbero dover assumere lo stesso valore; più tag con eguale gerarchia potrebbero dover avere gli stessi attributi; valori di attributo identici potrebbero dover avere lo stesso nome di attributo.
Diagramma di flusso per l’algoritmo implementato all’interno del tool di supporto all’armonizzazione NormaTEI
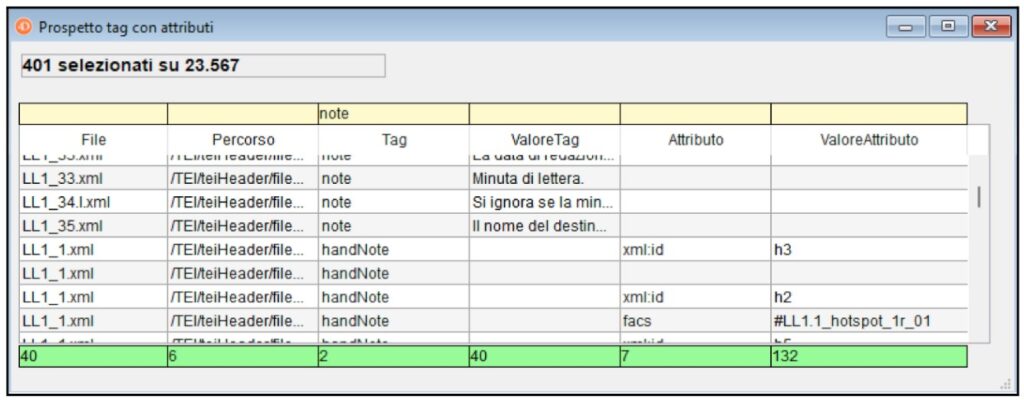
Il tool possiede una sua specifica interfaccia di ricerca e consente l’esportazione dei dati (tag, percorso, profondità, attributi, valori) in fogli di calcolo Excel.
Interfaccia di ricerca del tool NormaTEI
L’utilizzo del tool NormaTEI all’interno del progetto BDC ha posto in evidenza il sostanziale dimezzamento del numero dei differenti percorsi XML-TEI (1148) annotati nell’iniziale codifica degli elaborati, rispetto al conteggio effettuato dopo la fase di armonizzazione (594).
In aggiunta allo specifico strumento di ricerca, vengono messi a disposizione ulteriori strumenti di natura statistica che consentono sia un’analisi della distribuzione dei fenomeni testuali sia un controllo sulla consistenza dei dati.
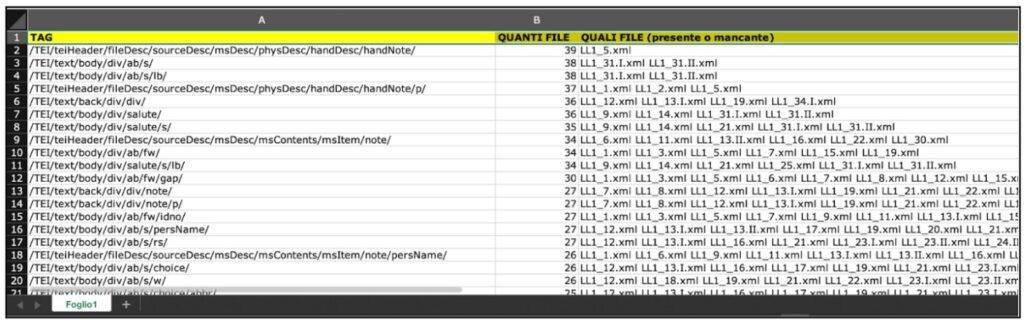
I tool generano una struttura a frame costituita da molteplici colonne: la prima colonna contiene un singolo tag oppure un percorso completo e la seconda colonna mostra il numero di volte in cui quel fenomeno occorre. A partire dalla terza colonna vengono elencati il nome del documento in cui il tag/percorso non è presente (quando il fenomeno è presente in più della metà dei file) oppure i documenti in cui quel tag/percorso è presente (quando il fenomeno è presente in meno della metà dei file).
Struttura a frame dei dati estratti mediante l’uso di NormaTEI visualizzati
L’utilità dei tool risiede in due aspetti legati al tipo di output: 1) è possibile conoscere in quali documenti un fenomeno non è presente per controllare e analizzare il motivo della mancata presenza; 2) è possibile registrare i fenomeni al fine di controllare e analizzare il motivo della bassa frequenza di attestazione. In entrambi i casi il tool permette quindi di trovare errori e particolarità della codifica, oppure di controllare il motivo per cui un fenomeno è presente su gran parte del corpus ma non sul corpus completo.
Bellini Digital Correspondence, a cura di A. M. Del Grosso e D. Spampinato, 2017-2022, <http://bellinicorrespondence.cnr.it> [consultato in AAAA/MM/GG], ISBN: 0000-0000-0000-0000